FAsT-Match: Fast Affine Template Matching
Simon Korman1, Daniel Reichman2, Gilad Tsur2, Shai Avidan1
[Abstract] [Paper] [Presentation] [Source-code] [BibTex] [Proof of Thm. 3.1] [Net construction] [Experimental results] [The 'overlap' criterion]
 |  |
 |
 |
[Abstract] [Paper] [Presentation] [Source-code] [BibTex] [Proof of Thm. 3.1] [Net construction] [Experimental results] [The 'overlap' criterion]
| |
|
|
Fast-Match is a fast algorithm for approximate template matching under 2D affine transformations that minimizes the Sum-of-Absolute-Differences (SAD) error measure. There is a huge number of transformations to consider but we prove that they can be sampled using a density that depends on the smoothness of the image. For each potential transformation, we approximate the SAD error using a sublinear algorithm that randomly examines only a small number of pixels. We further accelerate the algorithm using a branch-and-bound scheme. As images are known to be piecewise smooth, the result is a practical affine template matching algorithm with approximation guarantees, which takes a few seconds to run on a standard machine. We perform several experiments on three different datasets, and report very good results. To the best of our knowledge, this is the first template matching algorithm which is guaranteed to handle arbitrary 2D affine transformations.
"FAsT-Match: Fast Affine Template Matching"
[pdf]
Simon Korman,
Daniel Reichman,
Gilad Tsur,
Shai Avidan
CVPR 2013, Portland
Version 1.0 (4.3 MB zip file) Version 2.0 (4.4 MB zip file) Version 3.0 (4.3 MB zip file)
| BLUR | Template Dimension: 50% | Template Dimension: 20% | Template Dimension: 10% |
| Blur Level 0 | |
 |
 |
| Blur Level 1 |  |
 |
 |
| Blur Level 2 |  |
 |
 |
| Blur Level 3 |  |
 |
 |
| Blur Level 4 |  |
 |
 |
| Blur Level 5 | 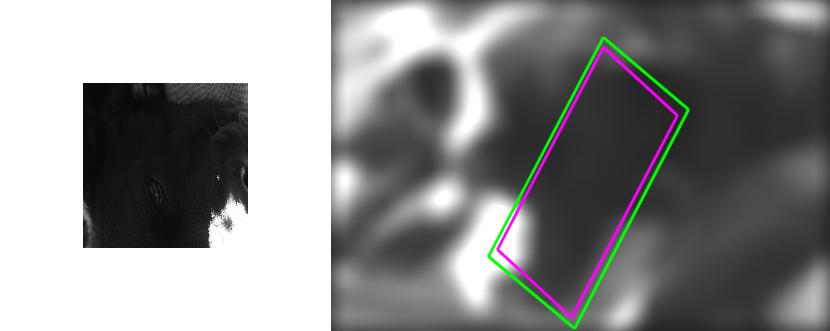 |
 |
 |
| NOISE | Template Dimension: 50% | Template Dimension: 20% | Template Dimension: 10% |
| Noise Level 0 |  |
 |
 |
| Noise Level 1 | 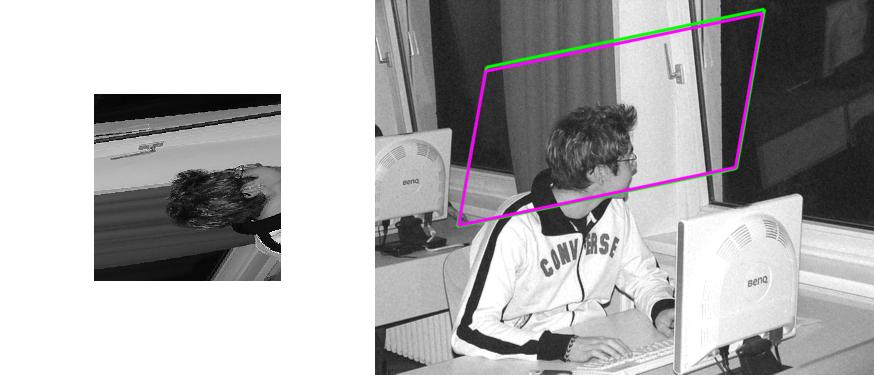 |
|
 |
| Noise Level 2 |  |
 |
 |
| Noise Level 3 |  |
 |
 |
| Noise Level 4 | 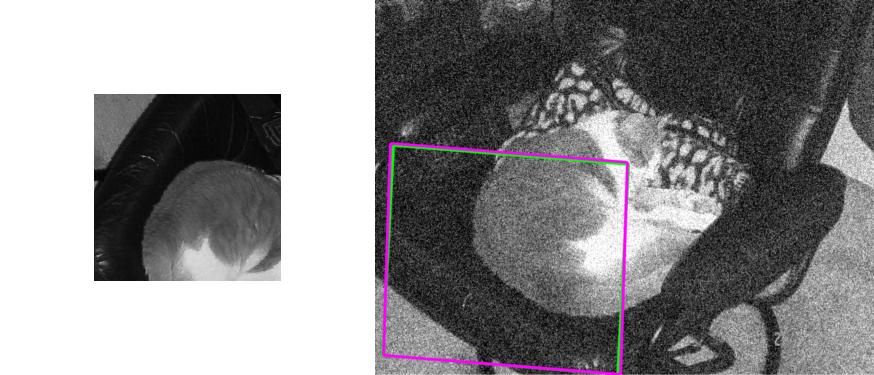 |
 |
 |
| Noise Level 5 |  |
|
|
| JPEG | Template Dimension: 50% | Template Dimension: 20% | Template Dimension: 10% |
| JPEG Level 0 |  |
 |
 |
| JPEG Level 1 |  |
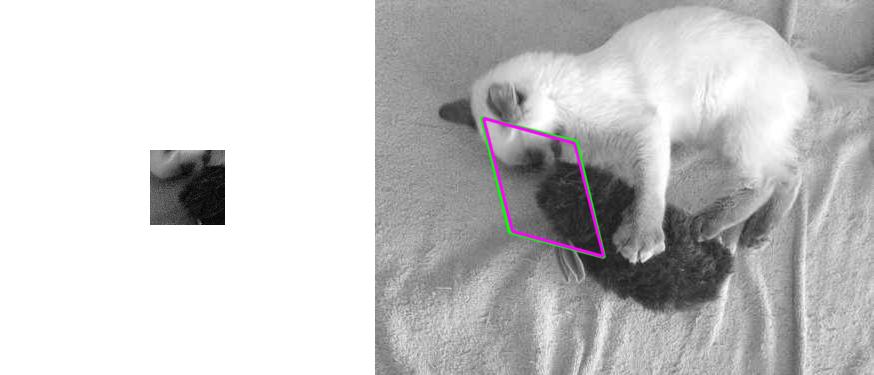 |
 |
| JPEG Level 2 |  |
 |
 |
| JPEG Level 3 |  |
 |
 |
| JPEG Level 4 |  |
 |
 |
| JPEG Level 5 |  |
 |
 |
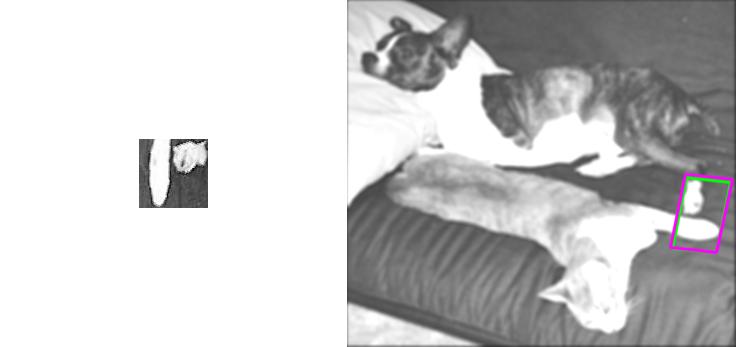
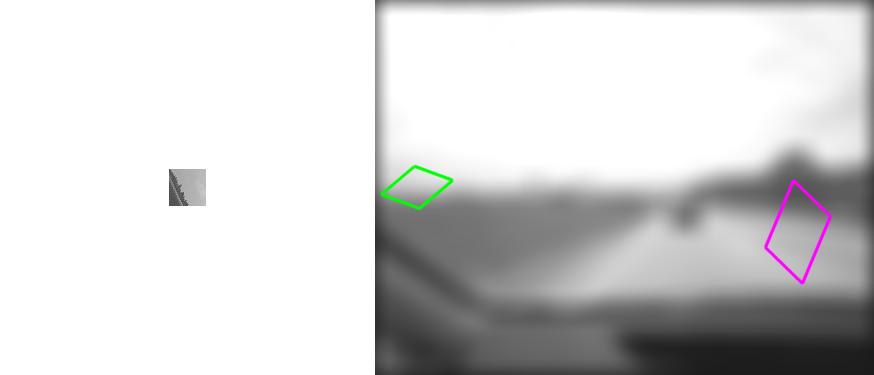
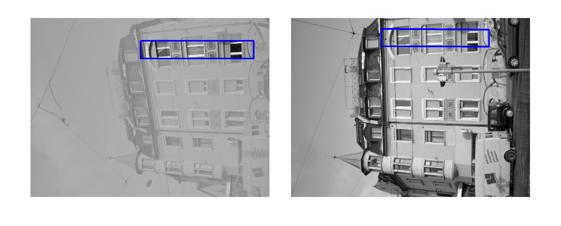
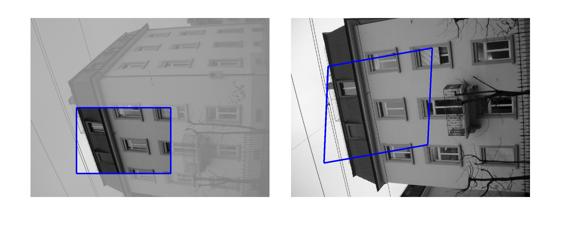
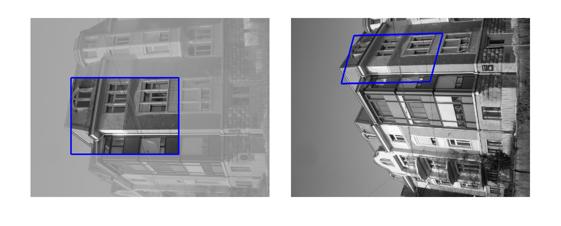
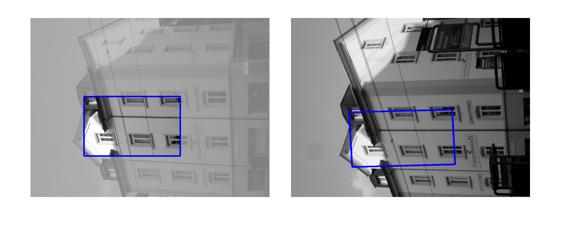
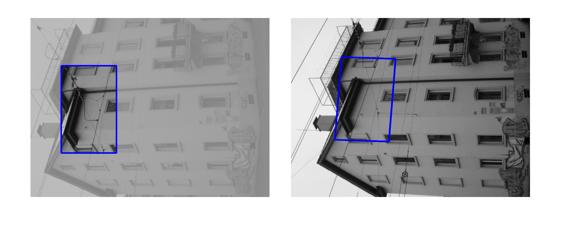
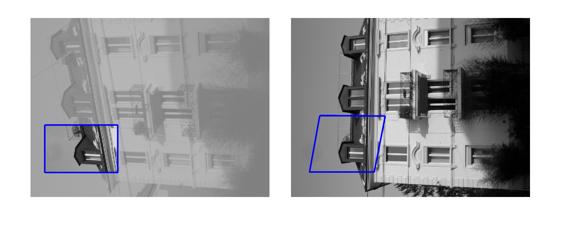
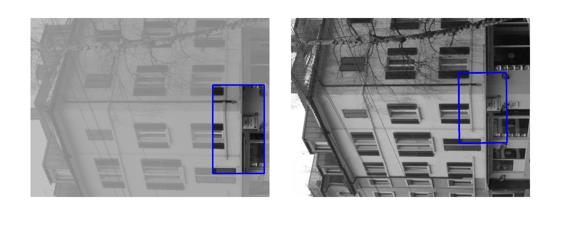
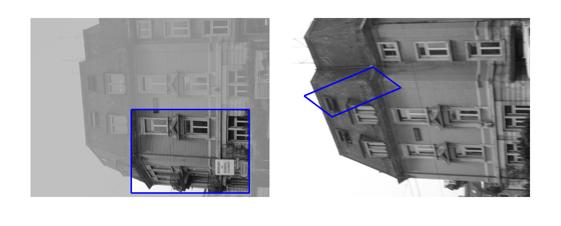
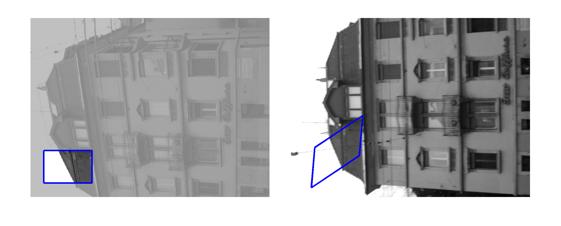
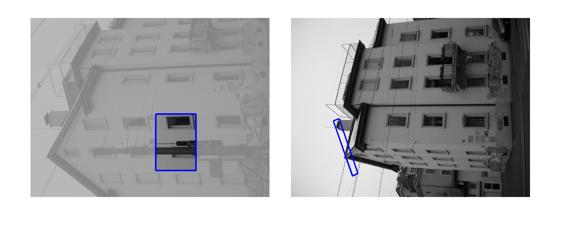
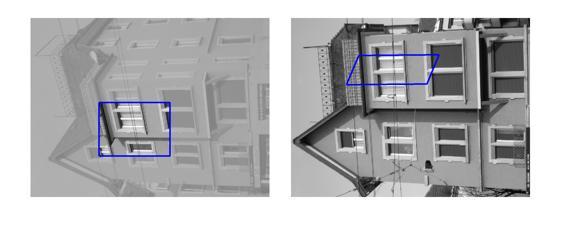
| Sequence | Query Template (in image 1) |
Findings in images 2-6 (green = GT Quadrilateral, blue = Fast-Match Parallelogram) |
| wall (view-point) |  |
 |
| graffiti (view-point) |  |
 |
| bikes (blur) |  |
 |
| trees (blur) |  |
 |
| bark (zoom+rotation) |  |
 |
| boat (zoom+rotation) |  |
 |
| light (illumination-change) |  |
 |
| UBC (JPEG-compression) |  |
 |
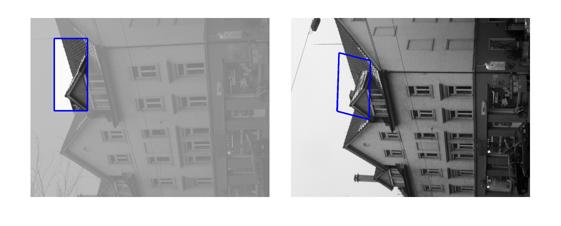
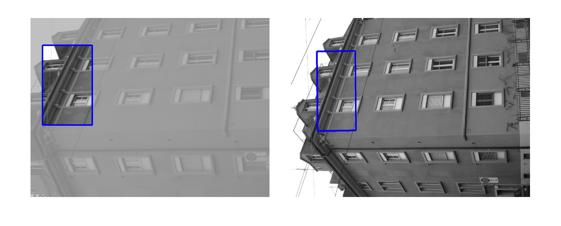
[Good (128 instances)] : In these cases Fast-Match seems to capture the correct location (finds a parallelogram, under an affinity, which matches well the correct region, which generally cannot be defined by an affinity or even a homography).
[Occluded (12 instances)] : These are cases where in either the template itself or in the area to which the template should be matched there is an obstacle, which doesn't appear in the other side.
[Out of Image/Plane (40 instances)] : These cases are of 2 types: 1) Either the template doesn't entirely map into the target image. 2) Or, the template includes at least 2 very different dominant planes (in these cases, affine transformations cannot explain the mapping).
[Bad (19 instances)] : In these cases Fast-Match did not find the correct area, and the reason isn't one of the above (occluded, out of plane/image).
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
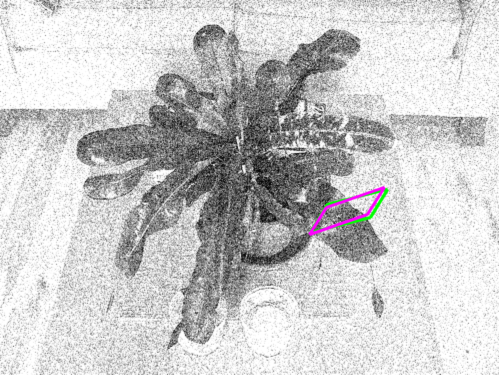
| 'SUCCESS CASES' (just under the 20% threshold) |
 |
 |
 |
 |
 |
| overlaps: | 17.6% | 17.9% | 19.1% | 18.2% | 18.4% |
 |
 |
 |
 |
 |
 |
| 18.3% | 17.8% | 16.9% | 16.6% | 15.4% | 15.1% |
| 'FAILURE CASES' (just over the 20% threshold) |
 |
 |
 |
 |
| overlaps: | 20.0% | 20.5% | 23.4% | 23.2% |
 |
 |
 |
 |
 |
| 20.9% | 21.9% | 24.2% | 24.2% | 24.1% |